Memoria en IA: cómo recuerdan y personalizan respuestas
La memoria en inteligencia artificial transforma la interacción con los usuarios. Modelos como ChatGPT pueden recordar interacciones previas para ofrecer respuestas más personalizadas y mejorar la eficiencia en la comunicación. Sin embargo, la memoria en IA tiene límites, como la actualización automática de datos y la gestión del contexto. Existen distintos tipos de memoria en IA, cada uno más adecuado según el caso de uso y la necesidad de persistencia.
Memoria en las aplicaciones IA
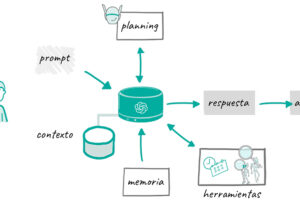
La inteligencia artificial está en una carrera por parecer más humana, y en esa carrera, la memoria es su gran desafío. Sin memoria, cada interacción es una historia que empieza desde cero, como si habláramos con alguien que, tras cada conversación, olvida todo lo que le hemos contado. Pero ¿qué pasa cuando una IA empieza a recordar? La «Memoria en IA» no es solo una cuestión de almacenar datos, sino de cómo se utilizan esos recuerdos para mejorar respuestas, anticipar necesidades y generar experiencias más personalizadas.
Los modelos de IA han evolucionado desde sistemas completamente amnésicos hasta otros capaces de recordar interacciones previas, adaptarse y, en algunos casos, incluso desarrollar una “personalidad” en función del historial del usuario. No obstante, no todas las inteligencias artificiales recuerdan de la misma manera ni con los mismos objetivos. Desde ChatGPT hasta los agentes de IA más avanzados, cada sistema tiene su propia forma de gestionar la memoria.
A lo largo de este post, exploraremos cada uno de estos enfoques en profundidad, identificando sus ventajas, limitaciones y aplicaciones estratégicas. Porque la verdadera pregunta no es si la IA puede recordar, sino qué recuerda, cómo lo hace y con qué propósito. Acompáñame en este recorrido para entender la memoria en IA y cómo está redefiniendo nuestra interacción con la IA.
Memoria en ChatGPT
Cuando hablamos de «Memoria en IA», uno de los nombres que inevitablemente surge es ChatGPT, la inteligencia artificial conversacional de OpenAI que ha ido evolucionando en su capacidad para recordar interacciones. Pero, ¿realmente ChatGPT tiene memoria? ¿Cómo gestiona la información entre sesiones? ¿Y qué implicaciones tiene esto para su uso en el día a día?
Memoria en ChatGPT: ¿cómo funciona y qué limitaciones tiene?
Uno de los avances más significativos en los modelos de OpenAI ha sido la introducción de la memoria en ChatGPT. Pero, ¿qué significa realmente que ChatGPT tenga memoria? ¿Hasta qué punto puede recordar información de sesiones pasadas? Si lo vemos de forma sencilla, ChatGPT con memoria es como una persona que recuerda algunos detalles de conversaciones anteriores, pero no tiene un registro exacto ni editable de todo.
¿Cómo funciona la memoria en ChatGPT?
Cuando la memoria está activada, ChatGPT almacena fragmentos de información de interacciones previas y los utiliza para personalizar sus respuestas. Esta memoria no es infinita ni perfecta; su capacidad actual está estimada entre 8.000 y 10.000 tokens, lo que equivale aproximadamente a 40 páginas de texto.
Además, ChatGPT no recuerda todo lo que le dices. Su memoria se actualiza automáticamente, lo que significa que selecciona qué información almacenar basándose en patrones de conversación. Este enfoque puede ser útil para mantener un contexto general con el usuario, pero también puede generar problemas.
Ventajas de la memoria en ChatGPT
- Experiencia personalizada: Puede recordar preferencias, temas de interés y estilo de comunicación del usuario.
- Mayor fluidez: No necesitas repetir constantemente información en sesiones consecutivas.
- Ahorro de tiempo: Ideal para usuarios frecuentes que buscan continuidad en sus conversaciones.
Limitaciones y desafíos de la memoria en ChatGPT
Aunque la memoria mejora la personalización, presenta tres grandes desafíos:
- Falta de control por parte del usuario: La memoria se actualiza sin previo aviso, lo que significa que ChatGPT puede almacenar datos irrelevantes o información errónea. Y no puedes decidir qué recordar o qué olvidar en tiempo real. Una estrategia para evitar que almacene información sin aprobación sería saturar la memoria con datos hasta el límite, impidiendo que registre nuevos elementos. Sin embargo, esto no es una solución práctica, ya que completar el equivalente a 40 páginas de información relevante y bien estructurada sobre lo que quieres que ChatGPT sepa sobre tu trabajo no es una tarea sencilla.
- Riesgo de sesgo y contaminación de respuestas. Si el modelo retiene información inexacta o mal interpretada, sus futuras respuestas pueden estar condicionadas por estos errores. A diferencia de un archivo editable, la memoria en ChatGPT no permite correcciones directas. En cambio, otros modelos como Gemini sí ofrecen la posibilidad de editar y gestionar la memoria de manera más precisa, lo que permite a los usuarios corregir o eliminar información específica para evitar respuestas erróneas o fuera de contexto.
- Dificultad para gestionar información dinámica: La memoria no se adapta bien a situaciones donde la información cambia constantemente (por ejemplo, actualizaciones de productos, cambios en normativa o nuevos datos de negocio). Si un usuario cambia de opinión sobre un tema, ChatGPT puede seguir anclado en datos antiguos. Además, esto puede generar problemas si gestionas múltiples proyectos con información sensible. Por ejemplo, si eres consultor y trabajas con varios clientes, la memoria podría trasladar datos concretos de un proyecto a otro sin contexto adecuado, lo que puede llevar a respuestas incorrectas o confusas. No es la primera vez que ocurre que, al estar en un proyecto, aparecen datos fuera de lugar, y solo al revisar la memoria se detecta el error. Esto puede comprometer la precisión de la información y generar confusión en la toma de decisiones.
¿Cómo se compara con otras formas de memoria en IA?
Si bien la memoria de ChatGPT es útil para mejorar la experiencia del usuario, sigue siendo más limitada que otros sistemas con memoria estructurada, como los Assistants de OpenAI o los Proyectos de ChatGPT. Mientras ChatGPT retiene información de manera automática pero sin un control detallado, otros modelos permiten una gestión más avanzada de los datos almacenados.
En resumen, la memoria en ChatGPT es un paso adelante en la personalización de la IA, pero todavía enfrenta desafíos en términos de control, persistencia y precisión. A medida que OpenAI continúe refinando esta función, podríamos ver modelos cada vez más adaptativos y eficientes en el manejo del contexto conversacional.
Memoria en proyectos de ChatGPT
¿Cómo funciona la memoria en los Proyectos de ChatGPT?
A diferencia del ChatGPT estándar, donde la memoria se basa en fragmentos de conversación seleccionados automáticamente, los Proyectos de ChatGPT utilizan un modelo de persistencia estructurada. Esto significa que pueden:
- Recordar detalles clave de interacciones pasadas y retomarlos en futuras sesiones sin necesidad de repetir información.
- Almacenar archivos y documentos, permitiendo que el modelo acceda a información relevante de manera más organizada.
- Clasificar y reutilizar información según objetivos empresariales, facilitando la colaboración dentro de equipos.
Este sistema convierte a los Proyectos de ChatGPT en una herramienta estratégica para empresas que buscan mejorar la gestión del conocimiento, evitando la pérdida de información entre sesiones y optimizando el tiempo de trabajo. La memoria en un proyecto se almacena en bases de datos internas y estructuras de embeddings dentro de los servidores de OpenAI.
Ventajas de la memoria en Proyectos de ChatGPT
- Memoria persistente real: La información clave no desaparece después de cada sesión.
- Optimización del trabajo en equipo: Ideal para proyectos colaborativos donde la continuidad del conocimiento es crucial.
- Capacidad de estructuración: Se pueden organizar datos de manera estratégica para facilitar el acceso y uso posterior.
Limitaciones
- No integra APIs externas: A diferencia de los Assistants de OpenAI, los Proyectos no pueden conectarse a bases de datos o fuentes de datos en tiempo real.
- No ofrecen personalización avanzada: No tienen la flexibilidad de los Custom GPTs en términos de ajuste de estilo y preferencias.
- Memoria no editable directamente: Los usuarios no pueden ver o modificar manualmente qué se guarda o se elimina.
Ejemplo práctico: Uso de la memoria en un Proyecto de ChatGPT
Imaginemos una empresa de consultoría que usa un Proyecto de ChatGPT para la gestión de clientes:
Un cliente pregunta sobre una estrategia de IA que discutió en una reunión anterior. En lugar de repetir toda la explicación, el modelo responde: «En la última sesión hablamos de automatización de procesos con IA. Mencionaste interés en modelos de predicción. ¿Quieres que exploremos más opciones?» Además, el usuario puede acceder a documentos previamente subidos con informes sobre la estrategia recomendada.
Los Proyectos de ChatGPT son una solución potente para empresas que necesitan memoria persistente y estructurada, diferenciándose del ChatGPT estándar y de los Custom GPTs. Sin embargo, para quienes buscan una gestión aún más avanzada del conocimiento, los Assistants de OpenAI pueden ser una mejor alternativa.
Memoria en Custom GPTs: ¿realmente recuerdan algo?
Uno de los errores más comunes al hablar de Custom GPTs es asumir que, por ser personalizables, también tienen memoria persistente. Sin embargo, la realidad es distinta: un Custom GPT no recuerda interacciones pasadas. Cada vez que inicias una nueva conversación, es como si estuvieras hablando con un modelo recién creado.
Entonces, ¿cómo es posible personalizar un Custom GPT sin que tenga memoria?
¿Cómo funcionan los Custom GPTs sin memoria?
Los Custom GPTs dependen de tres elementos clave para adaptarse a las necesidades de los usuarios sin necesidad de recordar información entre sesiones:
- Instrucciones personalizadas: Se configuran al crearlo y establecen el tono, estilo y enfoque de sus respuestas. Ejemplo: Un GPT para asesoría legal puede recibir instrucciones específicas para priorizar términos jurídicos en su lenguaje.
- Carga de archivos: Si un Custom GPT tiene habilitada la opción de procesar documentos, puedes cargar archivos de dos maneras:
- Subiéndolos a la Base de Conocimiento, lo que los convierte en permanentes y accesibles en futuras sesiones.
- Subiéndolos dentro de una conversación, en cuyo caso el GPT podrá acceder a ellos mientras dure la sesión, pero no los recordará en futuras interacciones, ya que no dispone de memoria sobre los chats.
Ejemplo: Si le subes un PDF sobre estrategias de marketing, podrá responder con base en ese contenido mientras dure la conversación, pero si vuelves más tarde, el archivo tendrá que subirse nuevamente, a menos que lo hayas guardado en la Base de Conocimiento.
-
Integración con herramientas externas: Puede conectarse a APIs o bases de datos para acceder a información en tiempo real. Ejemplo: Un Custom GPT diseñado para análisis financiero podría extraer datos de una API de mercado bursátil para generar informes actualizados.
Ventajas de los Custom GPTs sin memoria
- Personalización total: Puedes definir su comportamiento y estilo sin riesgo de que «olvide» información clave.
- Acceso a documentos y APIs: Si bien no recuerda, puede consultar bases de datos y archivos para ofrecer respuestas en tiempo real.
- Fiabilidad en las respuestas: Al no «contaminarse» con conversaciones previas, siempre responde según las instrucciones predefinidas.
Limitaciones
- No aprende de interacciones previas: Cada sesión es un nuevo comienzo, lo que puede ser frustrante en interacciones recurrentes.
- No retiene contexto: No puedes hacer referencia a conversaciones pasadas, salvo que subas archivos o utilices APIs.
- Depende de configuraciones manuales: Cualquier ajuste en el conocimiento del GPT debe hacerse manualmente en las instrucciones o mediante archivos cargados en cada sesión.
Ejemplo práctico
Supongamos que creamos un Custom GPT para soporte técnico de software:
Escenario 1: Un usuario pregunta «¿Cómo soluciono un error en mi software ERP?».
El Custom GPT responde con base en la documentación que tiene disponible en la sesión.
Escenario 2 (nueva sesión): El mismo usuario vuelve más tarde y pregunta «¿Recuerdas el problema que tenía con mi ERP?».
Respuesta del Custom GPT: «No tengo acceso a conversaciones anteriores. ¿Puedes describirme el problema nuevamente?»
Aquí es donde radica la principal diferencia con los Proyectos de ChatGPT, que sí recordarían el problema planteado previamente, y con los Assistants de OpenAI, que podrían almacenar información en una base de conocimiento persistente.
Los Custom GPTs no tienen memoria persistente, pero su flexibilidad y capacidad de integración con archivos y APIs los convierten en herramientas poderosas. Son ideales cuando necesitas un modelo altamente personalizable pero sin el riesgo de sesgos o contaminación de respuestas por interacciones pasadas.
Sin embargo, algo que sí puedes hacer es utilizar la conversación en ChatGPT con memoria y hacer una llamada a un Custom GPT utilizando «@». De esta forma, puedes combinar la memoria de ChatGPT con la información registrada en la sesión y, al mismo tiempo, aplicar la funcionalidad y conocimiento específico de un Custom GPT concreto. Esto te permite aprovechar lo mejor de ambos sistemas: la persistencia de información de ChatGPT y la especialización de los Custom GPTs.
Memoria en Assistants de OpenAI
Si ChatGPT con memoria ofrece una experiencia personalizada pero con limitaciones y los Custom GPTs dependen de configuraciones estáticas, los Assistants de OpenAI representan un equilibrio entre personalización y persistencia. Estos modelos están diseñados para almacenar información estructurada, integrarse con bases de conocimiento y acceder a datos externos, lo que los convierte en una opción potente para aplicaciones más avanzadas.
Pero, ¿cómo funciona realmente la memoria en los Assistants de OpenAI y en qué se diferencian de otras soluciones?
¿Cómo gestionan la memoria los Assistants de OpenAI?
A diferencia de ChatGPT con memoria, que selecciona automáticamente qué información recordar, los Assistants pueden retener información utilizando tres mecanismos clave:
Fine-tuning (ajuste fino del modelo)
Se entrena al modelo con ejemplos específicos para que aprenda patrones de respuesta que se mantendrán en el tiempo. Esto no es una «memoria» en tiempo real, pero permite que el Assistant se especialice en un área concreta.
Ejemplo: Un Assistant diseñado para atención al cliente puede entrenarse con un histórico de respuestas y casos de uso, asegurando consistencia en sus respuestas.
Vector stores (almacenamiento de datos estructurados)
Se pueden subir bases de conocimiento en documentos o bases de datos vectoriales. Esto permite al Assistant acceder a información relevante de forma persistente, pero sin «recordar» conversaciones como lo hace ChatGPT con memoria.
Ejemplo: Un Assistant en un despacho legal puede tener un repositorio con documentos jurídicos y consultarlos en cualquier momento.
Integración con APIs y herramientas externas
Los Assistants pueden conectarse a sistemas externos para recuperar información en tiempo real.
Ejemplo: Un Assistant financiero puede conectarse a APIs de mercado para ofrecer análisis de tendencias y reportes actualizados.
Ventajas de la memoria en Assistants de OpenAI
- Memoria más estructurada y persistente: Almacenan datos relevantes en bases de conocimiento accesibles en cualquier momento.
- Mayor precisión y fiabilidad: Gracias a los vector stores, los Assistants pueden recuperar información con alta relevancia contextual.
- Posibilidad de integraciones avanzadas: Pueden conectarse a herramientas y sistemas empresariales para enriquecer sus respuestas.
Limitaciones
- No recuerdan conversaciones como ChatGPT con memoria: Dependen de bases de datos y no de un «diálogo continuo».
- Requieren configuración avanzada: Para aprovechar al máximo su memoria, necesitan entrenamiento y estructuración de datos.
- No tienen una memoria emocional o conversacional: No retienen matices subjetivos de la interacción como sí lo hace ChatGPT con memoria.
Ejemplo práctico: Assistant de OpenAI en acción
Imaginemos que una empresa de consultoría en transformación digital usa un Assistant para gestionar información de clientes:
Escenario: Un cliente pregunta: «¿Cuáles son las mejores estrategias para la adopción de IA en pymes?» El Assistant consulta su vector store y responde con un resumen basado en los documentos previamente cargados.
¿Qué significa esto para la memoria en IA?
Los Assistants de OpenAI ofrecen una memoria más estructurada y controlable, lo que los convierte en la mejor opción para empresas y profesionales que necesitan persistencia sin perder precisión. Si bien no recuerdan conversaciones como ChatGPT con memoria, su capacidad de acceder a bases de datos y aprender de entrenamientos específicos los hace más robustos para aplicaciones avanzadas.
Mientras que ChatGPT con memoria es útil para interacciones fluidas y personalizadas y los Custom GPTs permiten configuraciones a medida sin memoria, los Assistants de OpenAI son la opción más potente cuando se necesita almacenar, organizar y consultar información con lógica empresarial.
El fine-tuning en un Assistant de OpenAI personaliza el modelo general (como GPT-4o) con la información específica que se le ha proporcionado durante el entrenamiento. Sin embargo, la información ajustada no se almacena en un vector store, sino que se integra directamente en los pesos del modelo. La aplicación de un trabajo de fine-tunning ajusta sus parámetros internos para reflejar los patrones y datos con los que ha sido entrenado. Esto significa que la información aportada ya no se encuentra como un conjunto separado de datos, sino que forma parte del modelo mismo y se usa de manera implícita en sus respuestas.
| Característica | ChatGPT con memoria | Proyectos de ChatGPT | Custom GPTs | Assistants de OpenAI |
| Memoria persistente | Sí (limitada) | Sí (persistencia en equipos) | No | Sí (vector stores, fine-tuning) |
| Capacidad de personalización | No | Sí (configuración estructurada) | Sí (instrucciones y archivos) | Sí (entrenamiento y APIs) |
| Recuerda interacciones previas | Sí (pero limitado) | Sí | No | No |
| Accede a bases de conocimiento | No | No | Sí (si usa APIs) | Sí (si usa APIs) |
| Aprende y mejora con el tiempo | No (excepto con memoria) | Sí (dentro del entorno de trabajo) | No (pero puedes subir nuevos archivos) | Sí (con fine-tunning y vector stores) |
| Toma de decisiones autónomas | No | No | No | No |
| Control del usuario sobre la memoria | Borrar, no editar | No | No | Parcial (depende del entrenamiento) |
| Integración con herramientas externas | No | No | Sí | Sí |
El futuro de la memoria en IA
La memoria en inteligencia artificial está evolucionando rápidamente, y con ella, la manera en que interactuamos con estos modelos. Desde simples asistentes conversacionales hasta agentes capaces de tomar decisiones estratégicas, la capacidad de recordar y aprender define el nivel de autonomía e inteligencia de cada sistema.
Pero lo realmente interesante es imaginar un futuro donde podamos configurar libremente cómo queremos que funcione la memoria en IA.
El sistema ideal: una memoria IA 100% personalizable
En un mundo donde la IA se adapta a nuestras necesidades, podríamos tener:
- Tamaño configurable de la ventana de contexto: Definir cuántos tokens queremos que la IA recuerde en una sesión.
- Almacenamiento flexible: Decidir si los datos se guardan en archivos, en un vector store, o si simplemente se eliminan tras la sesión.
- Fine-tuning del modelo del usuario: Un entrenamiento a medida que permita ajustar respuestas según nuestro estilo y necesidades.
- Control total sobre la memoria: Elegir entre registro automático o manual, asegurándonos de que solo se guarde lo que realmente queremos recordar.
- Edición de datos registrados: Poder revisar y modificar los recuerdos almacenados, como si tuviéramos una «configuración avanzada de memoria IA».
Por ahora, todo esto es un sueño, pero no uno imposible. La tendencia en IA apunta hacia modelos más adaptativos, configurables y transparentes, donde los usuarios tendrán mayor control sobre lo que la IA recuerda, cómo lo usa y con qué finalidad.
Porque el futuro de la memoria en IA no es solo recordar más, sino recordar mejor, de la manera que el usuario lo desee. Y tú, si pudieras diseñar tu IA perfecta, ¿cómo configurarías su memoria?
Para acabar con un poco de humor, veamos qué te cuenta ChatGPT con lo que tienes registrado en la memoria. Teclea literalmente: «roast me en español«… ya me cuentas!